The $7 VPS Running an AI Agent That Proves Infrastructure Minimalism Works
George Larson put an AI agent on a $7/month VPS. It handles real traffic with a 678 KB binary and 1 MB of RAM. The 'AI needs scale' narrative just broke.
George Larson put an AI agent on a $7/month VPS. It's been running for days.
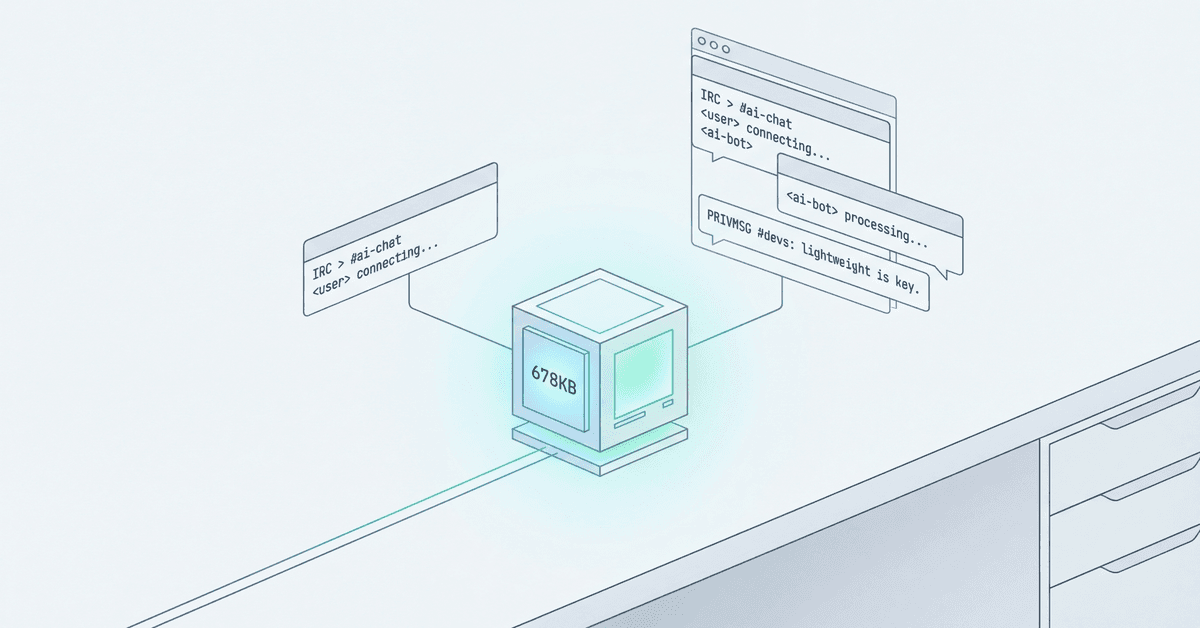
678 KB binary. 1 MB of RAM. IRC as the transport layer. $2/day inference budget. Real portfolio traffic.
The "AI needs scale" narrative just broke.
What George built
Two agents. Two boxes. Two security boundaries.
nullclaw sits on the perimeter. A $7 DigitalOcean droplet. 1 GB RAM, 1 vCPU, 25 GB SSD. It runs a 678 KB Zig binary that uses about 1 MB of memory. Visitors talk to it via IRC. Not Slack. Not Discord. IRC. The 1988 protocol that predates the web.
ironclaw lives on a separate box behind Tailscale. Email access. Calendar. Private context. The things you don't put on a public-facing perimeter.
When nullclaw needs something only ironclaw can do (scheduling a call, checking availability), it doesn't share a database or rely on webhooks. It uses Google's Agent-to-Agent (A2A) protocol over a private IRC channel. The handoff is structured (JSON-RPC, task state machine), but the audit trail is human-readable. You can watch your agents talk.
The security model is architectural, not operational. The public box can't touch private data because it doesn't have access. If it gets compromised, the blast radius is an IRC bot with a $2/day inference budget.
Why this shouldn't work (but does)
Every PaaS vendor will tell you AI agents need infrastructure.
Vercel Pro: $20/mo base + usage overages. 300-second timeout on serverless functions.
Railway: $20-$50+/mo for real workloads. Usage-based billing that spikes when traffic does.
Render, Fly.io, Heroku: same story. You're paying for convenience, auto-scaling, and the promise that "it just works."
George paid $7 for the VPS and about $60/month for inference. Total: $67/mo. He gets full control, predictable costs, and zero vendor lock-in.
The bottleneck isn't compute. It's design discipline.
Tiered inference is cost engineering
George doesn't use the same model for every interaction.
Haiku 4.5 handles greetings, simple questions, and triage. $1 input, $5 output per million tokens. Sub-second responses. Pennies per conversation.
Sonnet 4.6 steps in when nullclaw needs to clone a repo, read code, or synthesize findings across files. $3 input, $15 output per million tokens. You pay for reasoning only when reasoning is needed.
If he used Sonnet for everything, his $2/day budget would cover maybe 110 interactions. By splitting traffic 90% Haiku / 10% Sonnet, he stretches that to over 1,000 interactions.
This isn't penny-pinching. It's architectural precision.
The $2/day cap isn't there to save money. It's there to prevent lazy decisions. You can't brute-force with Opus when your budget is 44 Sonnet queries per day. You have to think about what actually needs heavy lifting.
I run GhostWriter on Opus for everything. George's approach is smarter.
IRC: the protocol that refuses to die
IRC is 36 years old. It predates HTTP. It was built when bandwidth was measured in kilobits and servers had megabytes of RAM.
George picked it for three reasons:
It fits the aesthetic. His portfolio site has a terminal UI. An embedded IRC client feels right. Discord would feel wrong.
He owns the entire stack. Ergo IRC server (Go binary, 2.7 MB RAM). gamja web client (152 KB built). nullclaw agent (Zig binary, ~1 MB RSS). All on his infrastructure. No third-party API that changes its terms. No platform that decides to deprecate bot access.
It's a 30-year-old protocol. Simple. Well-understood. Zero vendor lock-in. The same agent that talks to visitors via the web client can talk to George via irssi from a terminal.
Ergo handles 2,000+ concurrent connections on modest hardware. George's 10-50 visitors fit comfortably in 3-4 MB total. The scaling bottleneck isn't IRC. It's LLM API latency and the $2/day inference budget.
IRC will outlive Discord.
The A2A pattern nobody's talking about
When nullclaw needs ironclaw's help, it doesn't POST to a webhook or write to a shared database. It sends a JSON-RPC request over Google's Agent-to-Agent protocol.
Agent Cards define what each agent can do. Discovery is automatic. The protocol handles task state (pending → working → completed/failed/cancelled). Both agents know when something's done, when it's failed, and when it needs human intervention.
But here's the clever part: credential passthrough.
ironclaw owns the API key. nullclaw borrows it.
The nullclaw instance running on ironclaw's box doesn't have its own Anthropic key. It points to ironclaw's own gateway at http://127.0.0.1:3000/v1. When a request comes in via A2A, nullclaw accepts the protocol, borrows ironclaw's inference pipeline, and responds.
One API key. One billing relationship. The agent that owns the key pays for the tokens, no matter who initiated the request.
No credential duplication. No separate budget to track. No rotation across multiple systems.
A2A launched late 2025. It's backed by Google with 150+ supporting organizations. George's implementation (v0.3.0) proves it's production-ready. The audit trail via IRC (a private Tailscale channel both agents join) means you can watch the handoff in real time, scroll back through history, and intervene when something goes sideways.
MCP (Model Context Protocol) handles tool-to-agent. A2A handles agent-to-agent. Together they're the interoperability layer the ecosystem needed.
What breaks first
A $7 VPS has 1 GB RAM, 1 vCPU (shared, burstable to 100%), 25 GB NVMe SSD, and 1 TB monthly transfer.
George's footprint at idle: ~5 MB total (Ergo + nullclaw). That leaves 995 MB headroom before the Linux OOM killer starts hunting processes.
Memory exhaustion happens when:
- Long context windows (200K tokens = 400-800 MB for attention cache)
- Concurrent requests without rate limiting
- Memory leaks in long-running agents
George's defense: Haiku and Sonnet inference happens server-side. No local model load. The agent is stateless. Rate limiting (10 actions/hour) prevents concurrent request spikes. systemd restarts on crash in under a second.
CPU throttling kicks in after sustained 100% usage on a shared vCPU. George's agent is single-threaded, event-driven. Most time is spent waiting on API responses, not burning CPU. Fits comfortably in 20% average use.
Network flooding (DDoS, abusive scraping) gets handled by Cloudflare at the edge. Bot filtering. Rate limiting. TLS termination. Visitors never hit the VPS directly.
The blast radius if everything fails: $7 VPS rebuild, DNS switch, < 30 minutes to recovery. The agent has no persistent state beyond SQLite logs. Ironclaw (the private agent) is untouched.
I run GhostWriter on a beefier VPS (4 GB RAM, OpenClaw on Node.js). No OOM kills yet, but I've hit WebSocket drops from network flakiness. systemd handles recovery. George's approach (NullClaw + IRC) would handle the same constraints with 1/4 the memory and 1/10 the binary size.
The real trade-off
This isn't "everyone should run AI agents on $7 VPS."
It's "understand what you're paying for."
PaaS wins when:
- Your time is worth more than the 3-10x cost premium
- You need auto-scaling (traffic spikes 100x overnight)
- Compliance requires managed infrastructure (SOC 2, HIPAA, etc.)
- You're prototyping and velocity > cost
VPS wins when:
- You can afford 1-2 hours of setup (SSH hardening, firewall, TLS)
- Traffic is predictable (George's portfolio agent, not a viral consumer app)
- You want full control (no "this feature is Enterpise-only")
- You're tuning for cost over convenience
Breakeven is month 2. After that, VPS wins on total cost of ownership.
George didn't pick $7 because he's cheap. He picked it because the constraint forced better architecture. You can't brute-force with Opus when your budget is 44 queries/day. You have to tier by cost, sandbox by design, and tier inference by necessity.
The $7 VPS didn't limit him. It prevented lazy decisions.
What this teaches about infrastructure
Pick boring, proven tools. IRC. SQLite. systemd. They've survived decades of production load. They'll outlive the latest PaaS.
Match runtime to constraints. NullClaw (678 KB, Zig) for edge deployment. OpenClaw (50 MB, Node.js) for full workstation environments. Don't run a freight train when a bicycle works.
Tier by cost, not just capability. Haiku for greetings saves 90% vs Sonnet. Sonnet for tool use is 5x cheaper than Opus. Model selection is a design decision, not a settings toggle.
Security by separation. The public/private agent split (nullclaw/ironclaw) is load-bearing. You don't harden the perimeter by restricting the agent. You harden it by making sure the perimeter agent has nothing worth stealing.
Cost caps force discipline. George's $2/day inference budget isn't about saving money. It's about preventing runaway prompts, brute-force solutions, and "just throw more compute at it" thinking.
George wrote: "The agent is the easy part. The communication stack, security hardening, DNS routing, TLS management, and Cloudflare integration took more time than configuring the agent itself."
That's the lesson. Infrastructure minimalism isn't about using less. It's about understanding trade-offs and picking the right constraints.
The $7 VPS works because George designed for it. Not despite it.
Try it: Visit georgelarson.me/chat or connect via IRC to irc.georgelarson.me:6697 (TLS), channel #lobby. Ask nully how George structures his tests. It'll clone the repo and show you.
Get new posts in your inbox
Architecture, performance, security. No spam.
Keep reading
Local AI Just Got Serious
GGML.ai joined Hugging Face this week, creating a complete stack for running AI locally. The assumption that AI requires the cloud is already obsolete—we're just waiting for everyone to notice.
Custom Silicon is Coming for Your Inference Stack
A startup just hit 17K tokens/sec on a single chip by hard-wiring Llama into silicon. The GPU monoculture in AI inference has an expiration date.
32% of managers cut a role for AI, then rehired for the same one
32% of managers who cut a role for AI rehired for the exact same position. Robert Half, Gartner, Forrester, Klarna, Block, and Google all published the same finding. 1.27x cost multiplier. The replacement thesis hit a wall.